




機械学習を勉強し始めた方の中でこんな思いを持っている人いませんか?
ランダムフォレストって名前だけ聞いたことあるけど決定木と関係あるのかな?
今回はそんな疑問を解消するためにランダムフォレストとは何かを決定木と比べながら紹介します。さらにランダムフォレストを実際にpythonで実装していきます。
- ランダムフォレストって名前しか聞いたことのない人
- ランダムフォレストをpythonで実装してみたい人
決定木モデルが何かを振り返る
本題のランダムフォレストモデルに入る前に前提となる決定木モデルについておさらいしましょう。
決定木は分類の過程を可視化が可能であり意味解釈性が高い点が特徴でした。一方で木を深く成長させすぎると過学習を起こすという側面もありました。
ランダムフォレストはこの決定木を元にした学習モデルとなっています。
ランダムフォレストモデルとは
ランダムフォレストとはバギングの手法を決定木に採用したモデルです。
え、バギングって何ですか…
という方はこちらをまずはお読みください。

簡単に説明すると、複数の決定木モデルの平均や多数決により出力を決めるモデルです。
ただし、上の記事で実装した決定木ベースのバギングモデルとランダムフォレストは少しだけ異なります。その違いはランダムフォレストにおいて個々の決定木モデルの学習に使われる特徴量はランダムに選ばれたいくつかであるということです。
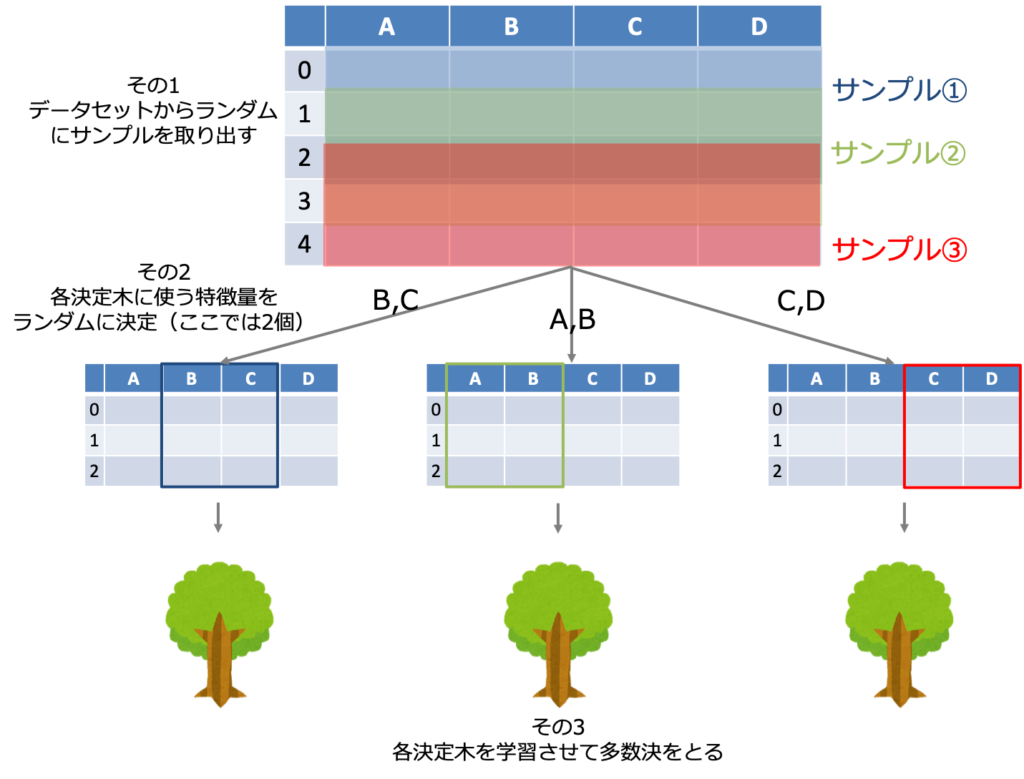
またランダムフォレストは複数の決定木のアンサンブルであるため単体の決定木のような意味解釈性は持ちません。以上をまとめると以下のようになります。
| 決定木 | バギング (決定木ベース) | ランダムフォレスト | |
| 木の数 | 1本 | 複数本 | 複数本 |
| 予測精度 | △ | ◯ | ◯ |
| 意味解釈性 | あり | なし | なし |
| 使う特徴量 | 全部 | 全部 | ランダムに決定 |
| 特徴量の重要度 | わからない | わからない | わかる |
重要な変数を判別する
ランダムフォレストが実用上優れている点はデータの分類に重要な特徴量が判別できるという点です。
この特徴をpythonを使って体感してみましょう。
ここでも使用するデータセットはバギングの記事で使ったWineデータセットです。「Wineデータセット?」という方はこちらをご覧ください。
学習に必要なデータを用意
モデルを構築して学習させるまではほとんど上の記事と一緒なのでサクサク進めていきます。
#pandasをインポート
import pandas as pd
#wineデータセットのインポート
from sklearn import datasets
wine = datasets.load_wine()
#特徴量とラベルを一つのデータフレームに結合(以下で特定のラベルを抽出するため)
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.DataFrame(wine.target, columns=['label'])
df_wine = pd.concat([X, y], axis=1)
#クラス1とクラス2のワインを選択
df_wine = df_wine[df_wine['label'] != 0]
X = df_wine.drop('label', axis=1).values
y = df_wine['label'].values
#クラスラベルを符号化
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
#訓練データとテストデータに分割
X_train2, X_test2, y_train2, y_test2 = train_test_split(X_all, y, test_size=0.20, stratify=y, random_state=1)モデルの構築
それではランダムフォレストモデルを構築していきます。今回は情報エントロピーを分割の基準として深さが3までの決定木をそれぞれ学習させていきます。
#ランダムフォレストのインスタンスを生成
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=300,
criterion='entropy',
max_depth=3,
bootstrap=True,
n_jobs=1,
random_state=1)
#モデルを学習させる
rf = rf.fit(X_train2, y_train2)特徴量の重要度を取得
ランダムフォレストモデルのfeature_importances_メソッドで学習に使用した特徴量の重要度が手に入るのでグラフに示します。
# 特徴量の重要度を出力 importances = rf.feature_importances_ # 特徴量の重要度をグラフに出力 n_features = len(wine.feature_names) plt.figure(figsize=(12, 8)) plt.barh(range(n_features), rf.feature_importances_ , align='center') plt.yticks(np.arange(n_features), wine.feature_names) plt.show()
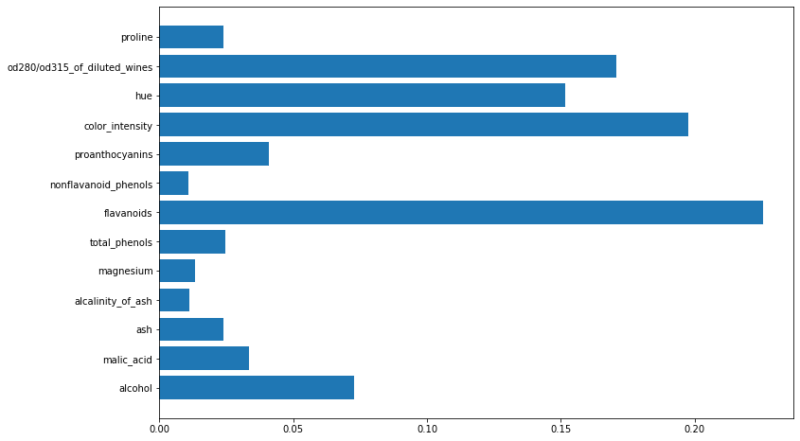
グラフを見るとワインの種類を分類するのに最も重要な特徴量は’flavanoids’(フラボノイドという有機化合物)であることがわかりました。
このようにランダムフォレストを使うことで分類時に重要な特徴量を判別することができます。重要な特徴量がわかれば分類に影響しない特徴量を除くことで学習の際に余計なノイズを取り除くことができます(特徴選択)。
そのためまずランダムフォレストで特徴量の重要度を把握して、その後重要な特徴量のみを選択して他のモデルで予測するという使われ方をします。
まとめ
- ランダムフォレストとは複数の決定木から出力を決める(バギング)手法
- 決定木のような意味解釈性はなくなるが重要な特徴量を判別可能

コメント