



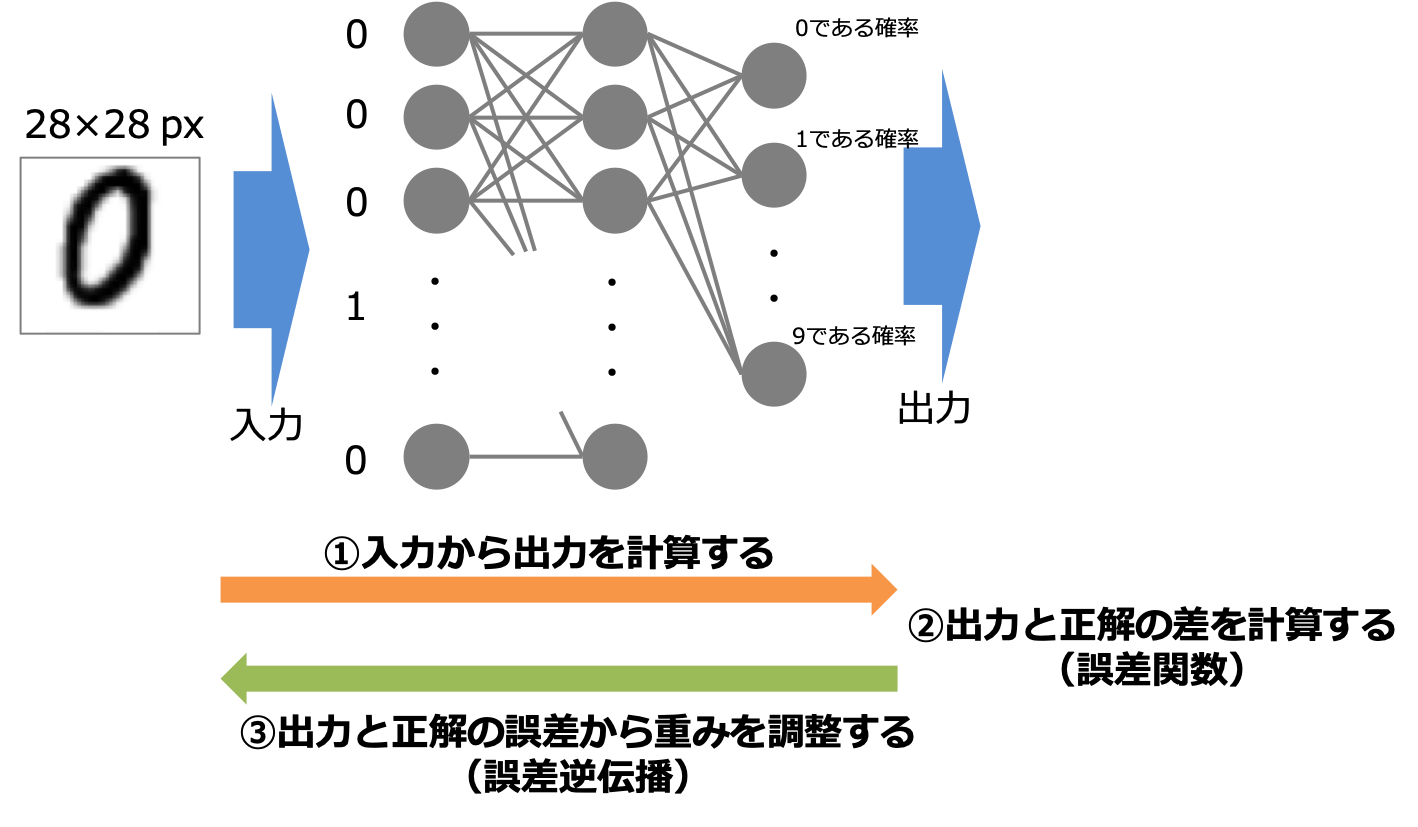
深層学習がどのような計算を経て学習しているのかを学びましょう。
本シリーズではニューラルネットワークがどのような計算を経て学習をするのか理論的側面を学び、実際に自分で実装することを目標としています。
本シリーズその1では深層学習計算において重要な以下の2点を導入しました。
- 与えられた入力から出力を計算する方法(順伝播計算)
- 得られた出力が正解とどれだけ離れているかの定量評価(誤差関数)
私たちは入力から出力を計算して、さらに得られた出力と正解との差を求めることができるようになりました。そこで今回は出力と正解の差を修正するようにニューラルネットワークを調整する誤差逆伝播法について紹介します。
勾配降下法による重みの最適化
私たちのひとまずの目標は計算して得られる出力を正解に近づけることです。出力を正解に近づけることは出力と正解の差を表現する誤差関数$E(\bm{w})$を最適化することに他なりません。
誤差関数の最適化には勾配降下法という手法が一般に用いられます。勾配降下法とは現在の変数$\bm{w}$から誤差関数の負の勾配方向に少し動かすという手順を繰り返すことで誤差関数を最適化するという手法です。
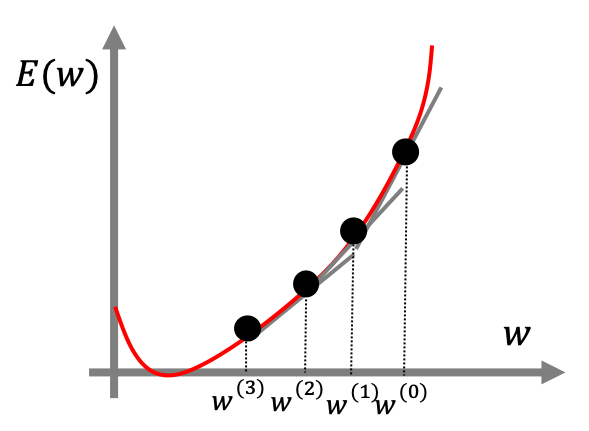
例えば誤差関数が上図のような関数で表される時、初期値の重み$w^{(0)}$から出発します。勾配降下法では以下のように計算していきます。
- 誤差関数の傾き(勾配)を計算する。今回は$\frac{dE(w)}{dw}$
- 負の勾配方向に少し移動して重みを更新する。$w^{(1)} = w^{(0)} – \eta\frac{dE(w)}{dw}$
- 1,2を繰り返す。何回も繰り返すと$E(w)$の最小値付近に収束する。
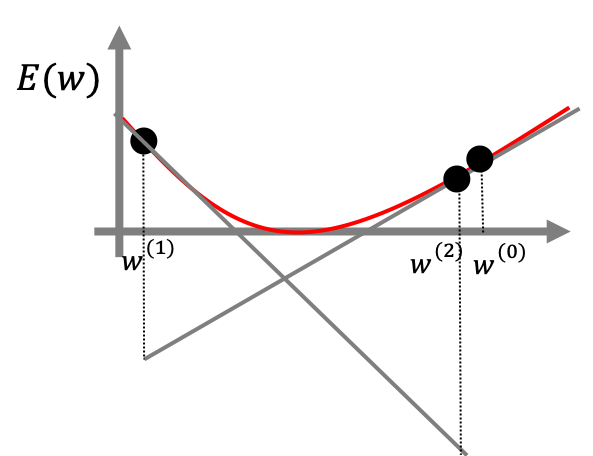
ここで$\eta$は学習係数といい重みをどれだけ大きく更新するかを調節する係数です。学習係数が大きいほど重みは早く収束しますが、大きすぎると下の図のようにスムーズに更新されないこともあるので適切に扱う必要があります。
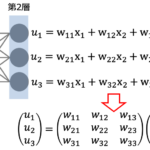
一般的にはニューラルネットワークにおける重みは各層の各ユニットに存在するため重みはベクトルで表されます。そのため勾配計算は以下のように表されます。
$\displaystyle \nabla E = [\frac{\partial E}{\partial w_1} \cdots \frac{\partial E}{\partial w_M}]^T$
つまりニューラルネットワークの重みを最適化するためには誤差関数の勾配を計算する必要があります。
誤差逆伝播法による微分計算
誤差関数の勾配を計算すれば良いということはわかりましたが、実はこの勾配計算はかなり面倒な計算です。
例えば代表的な誤差関数である二乗誤差$E_n = 1/2||\bm{y}(\bm{x}_n) – \bm{d}_n||$を例に考えてみます。第$l$層の重みの1つである$w_{ji}^{(l)}$で微分してみましょう。
$$\displaystyle \frac{\partial E_n}{\partial w_{ji}^{(l)}} = (\bm{y}(\bm{x}_n) – \bm{d}_n)^T \frac{\partial \bm{y}}{\partial w_{ji}^{(l)}}$$
右辺を計算する上で厄介なのが$\frac{\partial \bm{y}}{\partial w_{ji}^{(l)}}$です。なぜなら出力の$\bm{y}$は下の式を繰り返すことで計算されるからです。
$$\begin{aligned}\bm{u}^{(l+1)} &= \bm{w}^{(l+1)}\bm{x}^{(l)} + \bm{b}^{(l+1)} \\ \bm{z}^{(l+1)} &= f(\bm{u}^{(l+1)})\end{aligned}$$
つまり下のように活性化関数が何個も入れ子となったものを計算しなくてはならないのです。
$$\begin{aligned} \bm{y}(\bm{x}) &= f(\bm{u}^{(L)}) \\ &= f(\bm{W}^{(L)}\bm{z}^{(L-1)} + \bm{b}^{(L)}) \\ &= f(\bm{W}^{(L)} f(\bm{W}^{(L-1)}f(\cdots f(\bm{W}^{(l)}\bm{z}^{(l-1)} + \bm{b}^{(l)}) \cdots )) + \bm{b}^{(L)}) \end{aligned}$$
このような計算は計算量が大きくなってしまう上煩雑です。そこで考案されたのが誤差逆伝播法という手法です。
3層のネットワークにおける例
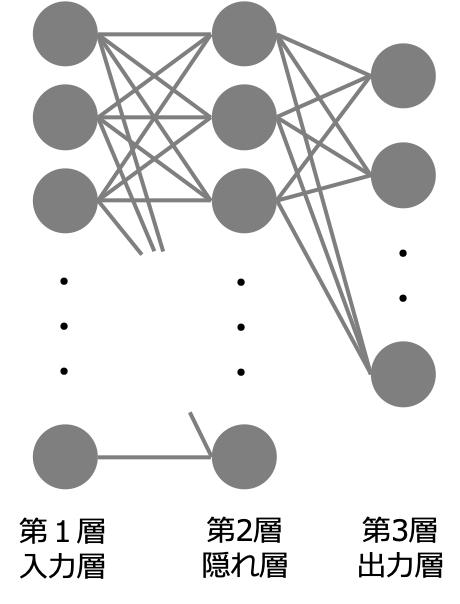
実際に計算を行うため3層(入力層を含む)のニューラルネットワークを考えます。この時出力層の活性化関数は$f(\bm{x}) = \bm{x}$ 、中間層の活性化関数は任意関数とします。また誤差関数には二乗誤差$E = 1/2||\bm{y}(\bm{x}_n) – \bm{d_n}||$を選ぶとします。
出力層と中間層における重みの微分$\frac{\partial E}{\partial w^{(3)}_{ji}}$と$\frac{\partial E}{\partial w^{(2)}_{ji}}$を計算します。
誤差関数を出力層の重みで微分
$$\begin{aligned} \displaystyle \frac{\partial E}{\partial w^{(3)}_{ji}} &= (\bm{y}(\bm{x}_n) – \bm{d}_n)^T \frac{\partial \bm{y} } {\partial w^{(3)}_{ji}} \\ &= (y_j(\bm{x}) – d_j) z^{(2)}_i \end{aligned}$$
出力層の重みに関する微分は簡単に計算することができます。
誤差関数を中間層の重みで微分
$$\displaystyle \frac{\partial E}{\partial w^{(2)}_{ji}} = \frac{\partial E}{\partial u^{(2)}_j}\frac{\partial u^{(2)}_j}{\partial w^{(2)}_{ji}}$$
ここで右辺の各項を計算します。まず$u^{(2)}_j = \sum_i w^{(2)}_{ji}z^{(1)}_i$であるから
$$\displaystyle \frac{\partial u^{(2)}_j}{\partial w^{(2)}_{ji}} = z^{(1)}_i$$
一方右辺第一項について
$$\displaystyle \frac{\partial E}{\partial u^{(2)}_j} = \sum_k \frac{\partial E}{\partial u^{(3)}_k}\frac{\partial u^{(3)}_k}{\partial u^{(2)}_j}$$
ここで$\displaystyle E = 1/2\sum_k (y_k(\bm{x})-d_k)^2 = 1/2\sum_k (u^{(3)}_k-d_k)^2$であるから
$$\displaystyle \frac{\partial E}{\partial u^{(3)}_k} = u^{(3)}_k-d_k$$
また$u^{(3)}_k = \sum_j w^{(3)}_{kj}f(u^{(2)}_j)$であるから
$$\displaystyle \frac{\partial u^{(3)}_k}{\partial u^{(2)}_j} = w^{(3)}_{kj}f’(u^{(2)}_j)$$
以上をまとめると中間層の重みに関する微分は下のように計算することができます。
$$\displaystyle \frac{\partial E}{\partial u^{(2)}_j} = (f’(u^{(2)}_j)\sum_k w^{(3)}_{kj}(u^{(3)}_k-d_k))z^{(1)}_i$$
一般のニューラルネットワーク
以上の議論は一般の$L$層ニューラルネットワークにも適用することができます。先程と同様に第$l$層における誤差関数の微分計算は以下のように表すことができます。
$$\displaystyle \frac{\partial E}{\partial w^{(l)}_{ji}} = \frac{\partial E}{\partial u^{(l)}_j}\frac{\partial u^{(l)}_j}{\partial w^{(l)}_ji}$$
ここで右辺の第一項は次のように書き換えることができます。
$$\displaystyle \frac{\partial E}{\partial u^{(l)}_j} = \sum_k \frac{\partial E}{\partial u^{(l+1)}_k}\frac{\partial u^{(l+1)}_k}{\partial u^{(l)}_j} $$
上の式の見通しをよくするために$\delta$という量を導入します。
$$\displaystyle \delta^{(l)}_j \equiv \frac{\partial E}{\partial u^{(l)}_j}$$
すると、先ほどの式はデルタを用いると3層ニューラルネットワークの計算と合わせて下のように書くことができます。
$$\displaystyle \delta^{(l)}_j = \sum_k \delta^{(l+1)}_j (w^{(l+1)}_{kj}f’(u^{(l)}_j))$$
つまり第$l$層のデルタは第$l+1$層のデルタから求めることができるということを表しています。この関係式を繰り返すと出力層の各デルタが求まれば任意の層のデルタを求めることができます。誤差逆伝播法というのは出力層から入力層に向かって伝播することに由来しています。
したがって勾配計算をするに当たって私たちは
- 出力層におけるデルタ $\delta^{(L)}_j \equiv \frac{\partial E}{\partial u^{(L)}_j}$
- 各層の活性化関数の導関数$f'(\bm{x})$
が求まれば良いということになります。勾配を求めることができれば重みを更新することができます。重みが更新できたら同じ計算を繰り返し行い誤差関数を最適化していくという流れです。
順伝播と逆伝播の行列を用いた計算
以上の計算は行列を用いて表すことが可能です。入力と出力の関係を行列を用いて以下のように表すことができます。
$$\begin{aligned} \bm{U}^{(l)} &= \bm{W}^{(l)} \bm{Z}^{(l-1)} + \bm{b}^{(l)} \bm{1}_N^T \\ \bm{Z}^{(l)} &= f^{(l)}(\bm{U}^{(l)})\end{aligned}$$
またデルタに関する逆伝播計算は次のように表すことができます。
$$\bm{\Delta}^{(l)} = f’^{(l)}(\bm{U}^{(l)}) \odot \bm{W}^{(l+1)T}\bm{\Delta}^{(l+1)}$$
ここで$\odot$は行列の各成分同士の積です。
そして計算された$\Delta$から誤差関数の勾配を求めて重みを更新します。
勾配消失問題
誤差逆伝播計算で注意したいこととして勾配消失問題というものがあります。勾配消失問題とは誤差伝播の計算は線形計算であるため、重みの値によってはと出力層から入力層にかけて急速に値が大きくなったり小さくなってしまい発散・または0に収束してしまう可能性があるという問題です。
近年までニューラルネットワークが多層化できなかった要因がこの勾配消失問題でした。しかしながら事前学習という手法が導入されたことで困難とされていた多層のニューラルネットワークの学習を可能としたのです。
まとめ
今回は得られた出力から重みを更新する手法である誤差逆伝播法について紹介しました。以上をまとめると次のような計算をすることになります。
- 入力から順伝播計算によって出力を求める
- 出力層においてデルタ$\delta^{(L)}_j = z_j – d_j$を求める。
- 出力層に近い順に中間層のデルタを逆伝播計算により求める。
- 誤差関数の各層の重みに対する微分を計算する。
- 計算した微分を用いて重みを更新する。
コメント