



複数の学習モデルを組み合わせて予測性能を向上させるアンサンブル学習の手法の一つであるブースティングについて紹介します。
バギングについてはこちらの記事を参考にしてください。

ブースティングとは
ブースティングとは予測性能がそれほど高くない単純な学習モデル(弱学習器)を複数用意して、前のモデルの学習結果と正解の差が改善するように次のモデルを一つずつ学習させる手法です。
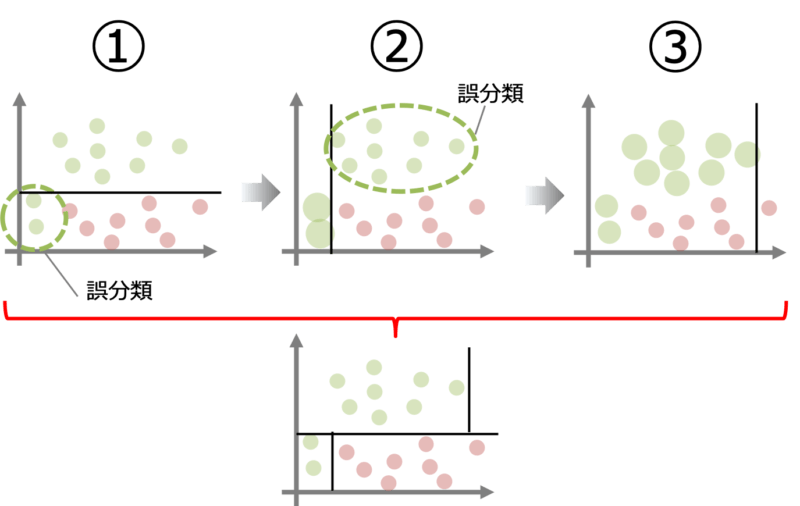
例えばデータが上図の①のように分布している場合を考えます。初めのモデルが赤と緑の分類境界を黒線のように定めると二つ緑の点が誤分類となります。
2つ目のモデルは1つ目のモデルが誤分類した点を修正するように学習を行います。すると2つ目のモデルは②の黒線のような分類境界を学習するでしょう。
以上のような学習を繰り返していくと最終的には赤枠の下のように分類精度の悪いモデルで繰り返し学習させることで分類精度の向上が期待できます。
ブースティングを実装する
それでは実際にブースティングをpythonで実装して学習結果を確かめてみましょう。ここではブースティングの代表的な手法である勾配ブースティング木(GBDT:Gradient Boosting Decision Tree)を例に取り上げます。
Wineデータセットを準備
バギングの記事と同様に今回も対象とするデータセットはWineデータセットを用います。使用する特徴量も前回同様’alcohol’と’od280/od315_of_diluted_wines’の二つとします。
- 13の特徴量(アルコール、リンゴ酸などワイン中の化学物質)
- ワインの等級を表す3種類のラベル
- サンプル数:178個(’0’ : 59個/‘1’ : 71個/‘2’ : 48個)
#pandasインポート
import pandas as pd
#wineデータセットのインポート
from sklearn import datasets
wine = datasets.load_wine()
#特徴量とラベルを一つのデータフレームに結合(以下で特定のラベルを抽出するため)
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.DataFrame(wine.target, columns=['label'])
df_wine = pd.concat([X, y], axis=1)
#クラス1とクラス2のワインを選択
df_wine = df_wine[df_wine['label'] != 0]
#特徴量は'od280/od315_of_diluted_wines',とalcohol'の2つを使用
X = df_wine[['od280/od315_of_diluted_wines', 'alcohol']].values
y = df_wine['label'].values
#クラスラベルを符号化
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
#データセットを訓練データとテストデータに分割する
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y, random_state=1)学習モデルを構築して学習させる
データの準備が終わったら学習モデルを構築します。勾配ブースティング木はscikit-learnに実装されているため呼び出すだけで使用することができます。
今回は500個の決定木(弱学習器)を用いて学習させることにします。
#勾配ブースティング木モデルを構築する
from sklearn.ensemble import GradientBoostingClassifier
gbdt = GradientBoostingClassifier(n_estimators=500,
learning_rate=0.1,
random_state=1)
#モデルを学習させる
gbdt = gbdt.fit(X_train, y_train)
#学習結果を確認する
from sklearn.metrics import accuracy_score
y_train_pred = gbdt.predict(X_train)
y_test_pred = gbdt.predict(X_test)
score_train = accuracy_score(y_train, y_train_pred)
score_test = accuracy_score(y_test, y_test_pred)
print('accuracy score of decision tree : %.3f/%.3f' % (score_train, score_test))
#==>accuracy score of decision tree : 1.000/0.875構築したモデルの予測精度は訓練データで100%、テストデータで87.5%であるということがわかりました。若干過学習気味です。
学習結果を可視化する
学習結果を可視化してみましょう(下図右)。グラフ化の方法については下記リンクのバギングの記事を参考にしてください。
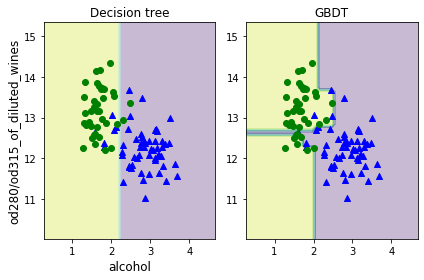
参考のため一本の決定木で学習させた結果を左側に載せています。ブースティングによって単一の決定木よりもデータ構造をより捉えていることが確認できます。
ここで注意したいのはブースティングを含むアンサンブル学習は単一の学習モデルと比べて計算の複雑さが大きくなりやすいということです。
特に勾配ブースティング木は欠損値を扱うことができるなど使いやすく多くの人が採用しているモデルではありますが、計算コストと相談して採用するかどうかを決める必要がありそうです。
まとめ
- ブースティングはアンサンブル学習の一つ
- 前のモデルの学習結果を改善するように次のモデルが学習を進めていく
- ブースティングを含むアンサンブル学習は計算が複雑になりやすいので注意が必要

コメント