





予測精度の高いモデルを作るにはどうすればいいのでしょうか?
与えられた訓練データを正確に予測する学習モデルを構築しても、未知のデータに対して予測精度がは高くはなりません(過学習)。機械学習の学習モデルを構築する上で過学習への配慮は重要です。
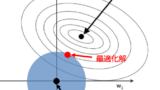
モデルを適切に構築するためにはバリアンスとバイアスを適切に調整する必要がありました。
適切な予測モデルを構築するためにはモデルの性能評価が不可欠です。ここではモデルの性能評価の手法であるホールドアウト法(holdout)と交差検証法(cross validation)について紹介します。
ホールドアウト法
手元にあるデータセットで学習モデルの性能を評価しようと思うと、考えつく最も簡単な手法はデータセットを訓練データと検証用のテストデータに分割してモデル評価を行うことです。これをホールドアウト法(holdout)といいます。
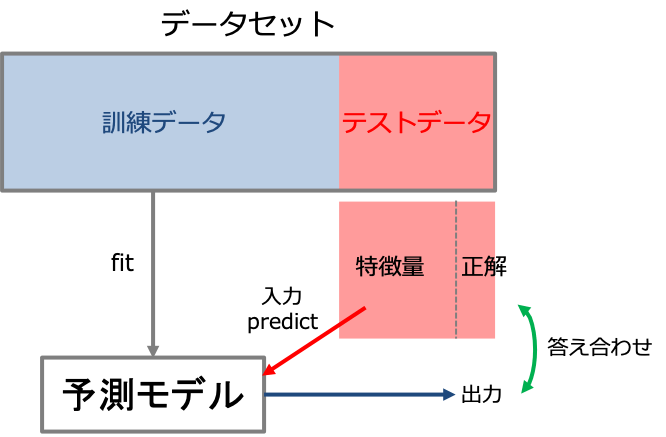
ホールドアウト法はデータセットを訓練データとテストデータに分割し、訓練データを使って学習モデルを構築し、テストデータを入力した時の出力を答え合わせすることで予測精度を検証します。
ただしこの手法には問題点があり、データの分割の仕方によって性能評価に影響が出る可能性があるということです。
例えば偶然テストデータに予測の難しいデータが入っている場合は予測性能が低く見積もられる可能性があります。そういった性能評価のばらつきを抑えるために考案されたのが交差検証法(cross vlidation)です。
交差検証法(cross validation)
交差検証法とはデータセットをランダムにk分割して、1つをテストデータ残りをテストデータに使用して性能評価を行うという手順をk回繰り返して性能を推定するという手法です。
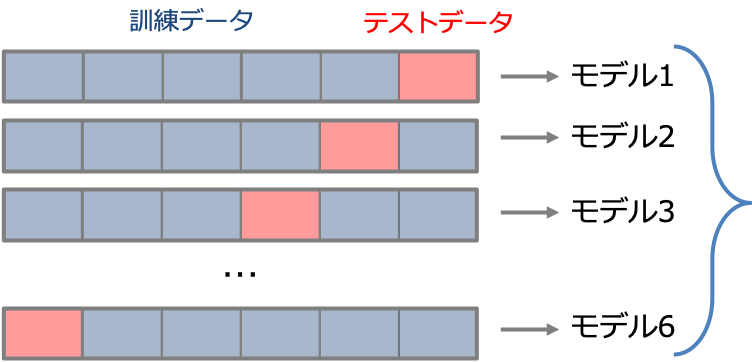
交差検証法は先ほどのホールドアウト法と比べてこのようなメリットがあります。
では実際にscikit-learnを使って交差検証によるモデル評価を行っていきます。
Irisデータセットを読み込んで分割する
データはIrisデータセットを使用します。
Irisデータってなんだ
っていう方はこちらをご覧ください。
まずはデータセットを読み込み訓練データとテストデータに分割します。
#Irisデータセットを読み込む from sklearn import datasets iris = datasets.load_iris() X = iris.data[:, :2] #特徴量は最初の2つを使う y = iris.target #訓練データとテストデータに分割する from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y, random_state=1)
交差検証を使ってモデルを検証する
交差検証をするにあたってまずはデータをk分割します。KFoldというクラスを使ってデータの分割方法を指定します。今回は5分割とします。
#データの分割方法を指定する(5分割) from sklearn.model_selection import KFold kf = KFold(n_splits=5, shuffle=True)
#決定木モデルのインスタンスを作成する(木の深さは3と7) from sklearn.tree import DecisionTreeClassifier dtc3 = DecisionTreeClassifier(max_depth=3) dtc7 = DecisionTreeClassifier(max_depth=7
決定木モデルで交差検証する
モデルと訓練データ、テストデータ、データの分割方法を指定すれば一行でスコアを出すことができます。モデルの分割は先ほど指定したものを用います。
#交差検証によってスコアを計算する from sklearn.model_selection import cross_val_score dtc3_scores = cross_val_score(dtc3, X_train, y_train, cv=kf) dtc7_scores = cross_val_score(dtc7, X_train, y_train, cv=kf)
今回はデータを5分割しているので下の図のように5つのスコアが得られます。
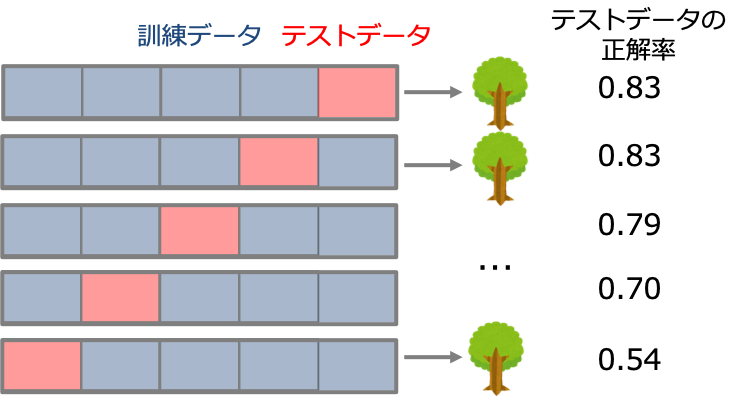
#木の深さが3のモデルのスコアを確認(5回分) dtc3_scores
Out:
array([0.83333333, 0.83333333, 0.79166667, 0.70833333, 0.54166667])
In :
#2つのモデルのスコアの平均と標準偏差を確認する
print('dtc3 mean : ', dtc3_scores.mean(), 'std :', dtc3_scores.std())
print('dtc7 mean : ', dtc7_scores.mean(), 'std :', dtc7_scores.std())Out:
dtc3 mean : 0.7416666666666667 std : 0.10992421631894102 dtc7 mean : 0.75 std : 0.058925565098878974
ここからわかるのは決定木の深さが3と7本ではどちらも予測性能は変わらずそれほど高くはないことがわかりました。この検証で良いスコアを出すモデルがあればそのモデルを採用します。今回の場合だと他のモデルを検討すべきということでしょう。
ハイパーパラメータのチューニング
しかし、いざ自分で試そうと思ってコードを書いているとこんな疑問が出てくるのではないでしょうか?
木の深さ(max_depth)っていろんな値が取れるんじゃないか?
とても自然な疑問だと思います。モデルを構築にあたってmax_depthなど私たちが自分の手で指定しなくてはいけない値(モデルの調整つまみのようなもの)はハイパーパラメータといい、性能の良いモデルを作るためにはハイパーパラメータの調整が必須です。
この問題にはグリッドサーチという手法がありますが、これは別の記事として紹介します。
コメント