



過学習を抑える正則化
正則化とはモデルの複雑性を抑えて過学習を防ぐ手法です。まずは正則化が必要となる過学習という問題について説明していきます。
過学習とは機械学習にはよくある問題で、下のように学習モデルが訓練データに過剰に適合してしまった結果未知のデータに対して十分な予測性能がなくなる(汎化されない)という問題です。
過学習が発生しているモデルをバリアンス(variance)が高いと言います。
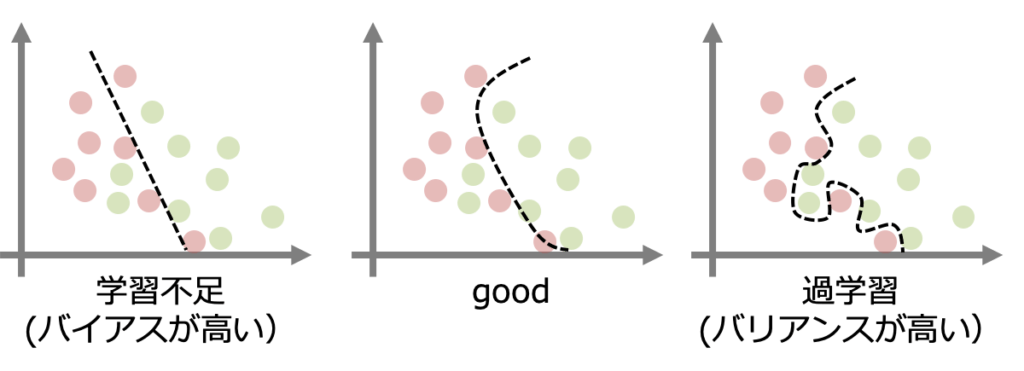
一方でモデルを単純化しすぎると上のようにデータのパターンを上手く表現できず、モデルの正確度が下がる問題が生じます。このようなモデルはバイアス(bias)が高いと言います。
- バリアンスとは日本語で分散と訳すように、モデルの予測のばらつきを表すものです。バリアンスの高いモデルでは訓練データのランダム性に敏感に反応します。
- バイアスとは偏差と訳すように、モデルが正しい値からどの程度外れているかを表すものです。
一般にバイアスとバリアンスはトレードオフの関係になっていて両者を同時に抑えることは不可能であり、最適なモデルを探る必要があります。
過学習の原因となるのは説明変数が多すぎる、または重みパラメータの値が極端に大きいことが考えられます。そこで使用されるのが正則化という手法です。
正則化をイメージで掴む
正則化は重みパラメータ(係数)に制限をかけることでモデルの複雑性を抑えています。
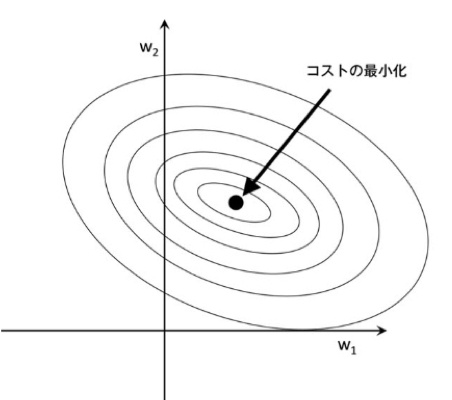
幾何学的なイメージを掴むために特徴量二つ(重みパラメータ$w$が二つ)の場合の学習を考えます。学習で最適化するコスト関数$J(\bf w)$は以下で表される誤差平方和とします。
$J(\bf w) = \frac{1}{2}{(\hat{y_1}-y_1)^2 + (\hat{y_2}-y_2)^2}$
ここで$\hat{y_i}$は$w_i$の関数とみなせるため、$w_1,w_2$に対して下の図のような等高線をプロットできます。この時円の中央にある点がコスト関数を最小にする点となります。
正則化は幾何学的に考えると、原点を中心とする図形内にコスト関数の最適化解が存在するように制限をかけることと言えます。なぜなら制限を最小化するのは原点の時で、コスト関数を最小とするのは円の中心の時であるため、解の範囲は二つの効果の競合によって決められるからです。
そのため解は制限を課した図形内でコスト関数が最小となる点となります。
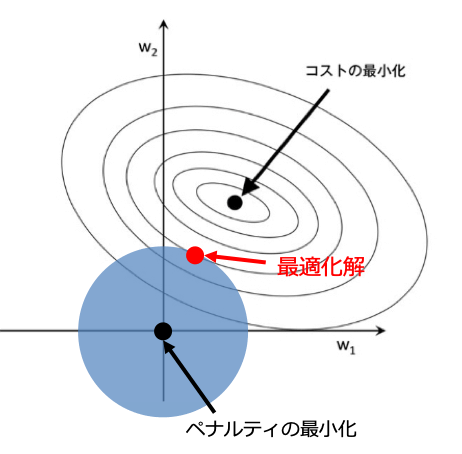
数式でいうとコスト関数に対して正則化項を加えた上で最適化を行なっています。ここで$\lambda$は正則化の強さを決める係数(ハイパーパラメータ)です。
$J(\bf w) = \frac{1}{2}{(\hat{y_1}-y_1)^2 + (\hat{y_2}-y_2)^2} + \lambda E(\bf w)$
この正則化項にはノルムが用いられ、用いるノルムに対応してL2正則化とL1正則化と言います。この二つが代表的な正則化の手法となるので紹介します。
L2正則化
L2正則化にはL2ノルムが用いられます。L2ノルムはよくベクトルの大きさとして定義される量です。
$L2: ||w||_2^2 = \sum_j w_j^2$
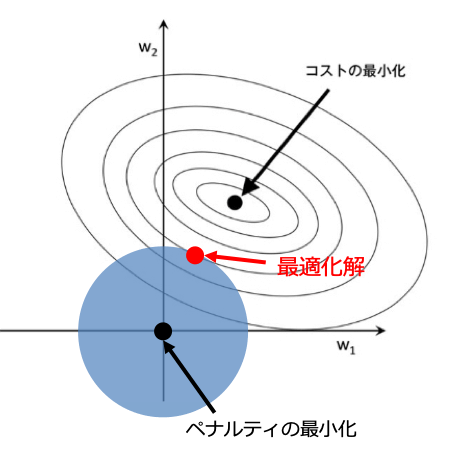
これは座標上では原点とのユークリッド距離で等距離の点の集合は円で表されます。またL2ノルムを罰則にとる回帰をRidge回帰と言います。
L1正則化
L1正則化にはL1ノルムが用いられます。L1ノルムは各パラメータの絶対値の和です。
$L1: ||w||_1 = \sum_j |w_j|$
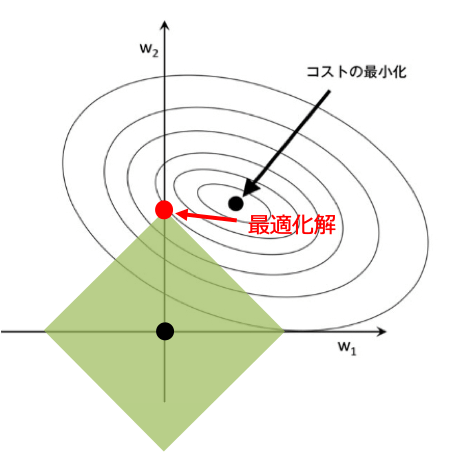
これは座標上では原点とのマンハッタン距離(座標系に沿って動いた距離)で等距離の点の集合はひし形で表されます。またL1ノルムを罰則にとる回帰をLasso回帰と言います。
L1正則化の大切な点は正則化の図形が角張っているため最適化解が軸上(図では$w_1=0$)に存在する可能性が高く、重みが0となる特徴量ができやすくなります。そのため重要な特徴量のみを選択する特徴選択に用いられることが多いです。
コメント